Quantifying how unlikely a player’s season-long shooting performance is, factoring in their prior shot history
Author
Tony ElHabr
Published
May 5, 2024
Modified
June 9, 2024
Introduction
Towards the end of each soccer season, we naturally start to look back at player stats, often looking to see who has performed worse compared to their past seasons. We may have different motivations for doing so–we may be trying to attribute team under-performance to individuals, we may be hypothesizing who is likely to be transferred, etc.
It’s not uncommon to ask “How unlikely was their shooting performance this season?” when looking at a player who has scored fewer goals than expected.1 For instance, if a striker only scores 8 goals on 12 expected goals (xG), their “underperformance” of 4 goals is stark, especially if they had scored more goals than their xG in prior seasons.
The ratio of a player \(p\)’s goals \(G_p\) to expected goals \(xG_p\)–the “performance” (\(PR_p\)) ratio–is a common, albeit flawed, way of evaluating a player’s shooting performance.2
\[
PR_p = \frac{G_p}{xG_p}
\]
An \(PR_p\) of 1 indicates that a player is scoring as many goals as expected; a ratio greater than 1 indicates overperformance; and a ratio less than 1 indicates underperformance. Our hypothetical player underperformed with \(PR_p = \frac{8}{12} = 0.67\).
In most cases, we have prior seasons of data to use when evaluating a player’s \(PR_p\) for a given season. For example, let’s say our hypothetical player scored 14 goals on 10 xG (\(PR_p = 1.4\)) in the season prior, and 12 goals on 8 xG (\(PR_p = 1.5\)) before that. A \(PR_p = 0.67\) after those seasons seems fairly unlikely, especially compared to an “average” player who has a \(PR_p = 1\) every year.
So how do we put a number on the unlikeliness of the \(PR_p = 0.67\) for our hypothetical player, accounting for their prior season-long performances?
Data
I’ll be using public data from FBref for the 2018/19 - 2023/24 seasons of the the Big Five European soccer leagues, updated through May 7. Fake data is nice for examples, but ultimately we want to test our methods on real data. Our intuition about the results can be a useful caliber of the sensibility of our results.
Get shot data
raw_shots <- worldfootballR::load_fb_match_shooting(country = COUNTRIES,tier = TIERS,gender = GENDERS,season_end_year = SEASON_END_YEARS)#> → Data last updated 2024-05-07 17:52:59 UTCnp_shots <- raw_shots |>## Drop penalties dplyr::filter(!dplyr::coalesce((Distance =='13'&round(as.double(xG), 2) ==0.79), FALSE) ) |> dplyr::transmute(season_end_year = Season_End_Year,team = Squad,player_id = Player_Href |>dirname() |>basename(),player = Player,match_date = lubridate::ymd(Date),match_id = MatchURL |>dirname() |>basename(),minute = Minute,g =as.integer(Outcome =='Goal'),xg =as.double(xG) ) |>## A handful of scored shots with empty xG dplyr::filter(!is.na(xg)) |> dplyr::arrange(season_end_year, player_id, match_date, minute)## Use the more commonly used name when a player ID is mapped to multiple names## (This "bug" happens because worldfootballR doesn't go back and re-scrape data## when fbref makes a name update.)player_name_mapping <- np_shots |> dplyr::count(player_id, player) |> dplyr::group_by(player_id) |> dplyr::slice_max(n, n =1, with_ties =FALSE) |> dplyr::ungroup() |> dplyr::distinct(player_id, player)player_season_np_shots <- np_shots |> dplyr::summarize(.by =c(player_id, season_end_year), shots = dplyr::n(), dplyr::across(c(g, xg), sum) ) |> dplyr::mutate(pr = g / xg ) |> dplyr::left_join( player_name_mapping,by = dplyr::join_by(player_id) ) |> dplyr::relocate(player, .after = player_id) |> dplyr::arrange(player_id, season_end_year)player_season_np_shots#> # A tibble: 15,327 × 7#> player_id player season_end_year shots g xg pr#> <chr> <chr> <int> <int> <int> <dbl> <dbl>#> 1 0000acda Marco Benassi 2018 70 5 4.01 1.25 #> 2 0000acda Marco Benassi 2019 59 7 5.61 1.25 #> 3 0000acda Marco Benassi 2020 20 1 1.01 0.990#> 4 0000acda Marco Benassi 2022 10 0 0.99 0 #> 5 0000acda Marco Benassi 2023 19 0 1.35 0 #> 6 000b3da6 Manuel Iturra 2018 2 0 0.41 0 #> 7 00242715 Moussa Niakhate 2018 16 0 1.43 0 #> 8 00242715 Moussa Niakhate 2019 10 1 1.5 0.667#> 9 00242715 Moussa Niakhate 2020 11 1 1.02 0.980#> 10 00242715 Moussa Niakhate 2021 9 2 1.56 1.28 #> # ℹ 15,307 more rows
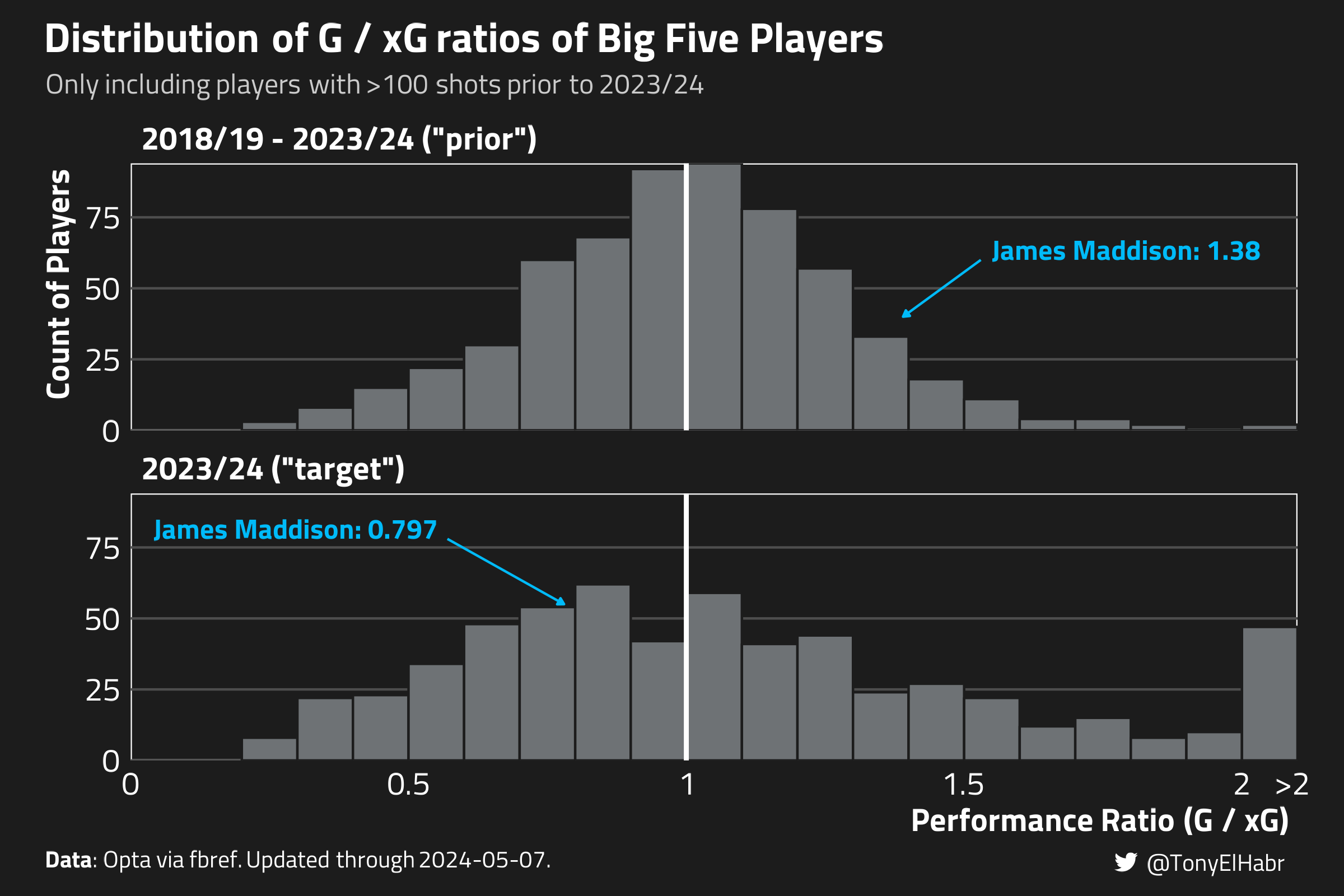
For illustrative purposes, we’ll focus on one player in particular–James Maddison. Maddison has had a sub-par 2023/2024 season by his own standards, underperforming his xG for the first time since he started playing in the Premier League in 2018/19.
Maddison’s season-by-season data
player_season_np_shots |> dplyr::filter(player =='James Maddison')#> # A tibble: 6 × 7#> player_id player season_end_year shots g xg pr#> <chr> <chr> <int> <int> <int> <dbl> <dbl>#> 1 ee38d9c5 James Maddison 2019 81 6 5.85 1.03 #> 2 ee38d9c5 James Maddison 2020 74 6 5.36 1.12 #> 3 ee38d9c5 James Maddison 2021 75 8 3.86 2.07 #> 4 ee38d9c5 James Maddison 2022 72 12 7.56 1.59 #> 5 ee38d9c5 James Maddison 2023 83 9 7.12 1.26 #> 6 ee38d9c5 James Maddison 2024 55 4 5.02 0.797
I’ll present 3 approaches to contextualizing the likelihood of a player underperforming relative to their prior \(G / xG\) ratio, which I’ll broadly call the “performance ratio percentile”, \(PRP_p\).
Weighted percentile ranking: Identify where a player’s performance relative to their own past ranks among the whole spectrum of player performances.
Resampling from prior shot history: Quantify the likelihood of the observed outcome for a given player by resampling shots from their past.
Evaluating a player-specific cumulative distribution function (CDF): Fit a distribution to represent a player’s past set of season-long outcomes, then identify where the target season’s outcome lies on that distribution.
I’ll discuss some of the strengths and weaknesses of each approach as we go along, then summarize the findings in the end.
Note that I use “prior”, or \(\text{target}'\), to refer to an aggregate of pre-2023/24 statistics, and “target” to refer to 2023/24. Here’s what the distribution of \(PR_{p,\text{target}'}\) and \(PR_{p,\text{target}}\) looks like. The latter’s distribution has a bit more noise–note the lump of players with ratios greater than 2–due to smaller sample sizes.
Approach 1: Weighted Percentile Ranking
The first approach I’ll present is a handcrafted “ranking” method.
Calculate the proportional difference between the pre-target and target season performance ratios for all players \(P\).
Calculate the the performance percentile \(PRP_p\) as a percentile rank of ascending \(\delta PR^w_p\), i.e. more negative \(\delta PR^w_p\) values correspond to a lower \(PRP_p\) percentile.4
With the data prepped in the correct manner, this is straightforward to calculate.
maddison_prp_approach1 |> dplyr::select(player, prior_pr, target_pr, prp)#> # A tibble: 1 × 4#> player prior_pr target_pr prp#> <chr> <dbl> <dbl> <dbl>#> 1 James Maddison 1.38 0.797 0.0233
This approach finds Maddison’s 2023/24 \(PR_p\) of 0.797 to be about a 2nd percentile outcome. Among the 602 players evaluated, Maddison’s 2023/24 \(PR_p\) ranks as the 15th lowest.
For context, here’s a look at the 10 players who underperformed the most in the 2023/24 season.
Ciro Immobile tops the list, with several other notable attacking players who had less than stellar seasons.
Discussion
Overall, I’d say that this methodology is straightforward and seems to generate fairly reasonable results. However, it certainly has its flaws.
Subjectivity in weighting: The choice to weight the difference in performance ratios by pre-2023/24 xG is inherently subjective. While it’s important to have some form of weighting–so as to avoid disproportionately emphasizing players with a shorter history of past shots or who shoot relatively few shots in the target season–alternative weighting strategies could lead to significantly different rankings.
Sensitivity to player pool: The percentile ranking of a player’s \(PR_{p,\text{target}}\) is highly sensitive to the comparison group. For instance, comparing forwards to defenders could skew results due to generally higher variability in defenders’ goal-to-expected goals ratios. Moreover, if we chose to evaluate a set of players from lower-tier leagues who generally score fewer goals than their expected goals, even players who can simply maintain a \(PR_p = 1\) might appear more favorably than they would when compared to Big Five league players. This potential for selection bias underlines the importance of carefully choosing the comparison set of players.
Approach 2: Resampling from Prior Shot History
There’s only so much you can do with player-season-level data; shot-level data can help us more robustly understand and quantify the uncertainty of shooting outcomes.
Here’s a “resampling” approach to quantify the performance ratio percentile \(PRP_p\) of a player in the target season:
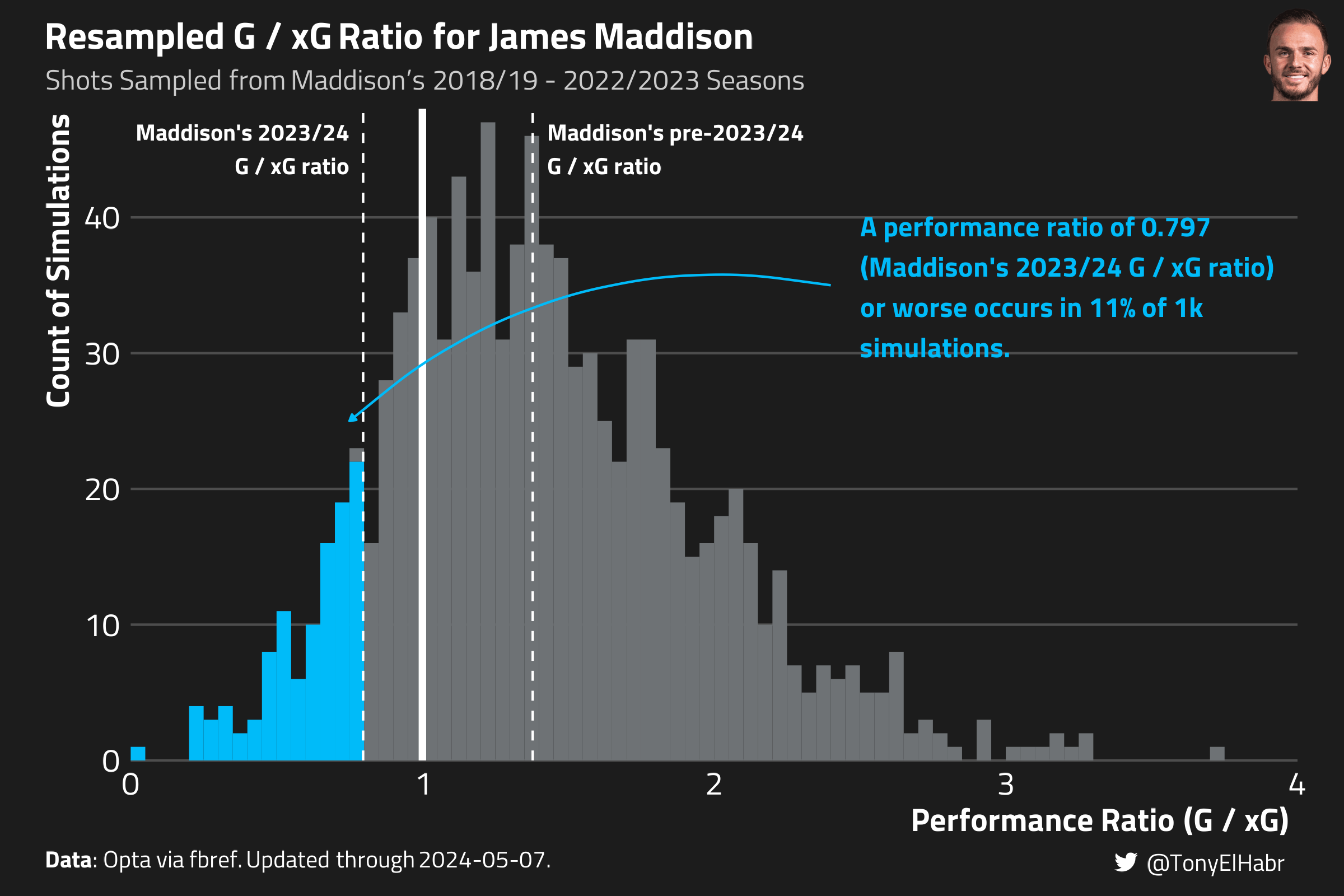
Sample \(N_{p,\text{target}}\) shots from a player’s past shots \(S_{p,\text{target}'}\). Repeat this for \(R\) resamples.5
Count the number of resamples \(r\) in which the performance ratio \(\hat{PR}_{p,\text{target}'}\) of the sampled shots is less than or equal to the observed \(PR_{p,\text{target}}\) in the target season for the player. The proportion \(PRP_p = \frac{r}{R}\) represents the unlikeness of a given player’s observed \(PR_{p,\text{target}}\) (or worse) in the target season.
maddison_prp_approach2 |> dplyr::select(player, prior_pr, target_pr, prp)#> # A tibble: 1 × 4#> player prior_pr target_pr prp#> <chr> <dbl> <dbl> <dbl>#> 1 James Maddison 1.38 0.797 0.109
The plot below should provide a bit of visual intuition as to what’s going on.
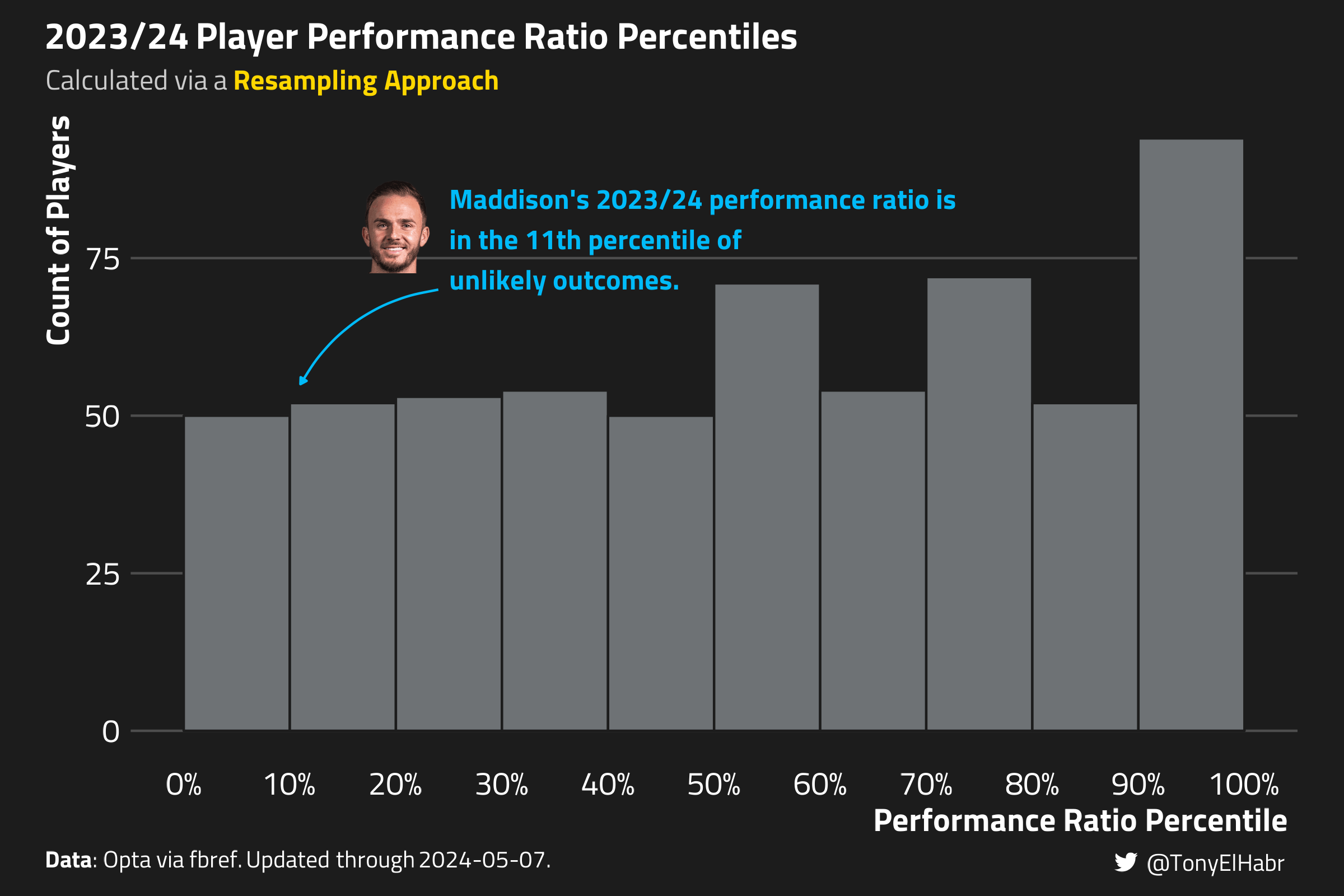
These results imply that Maddison’s 2023/24 \(G / xG\) ratio of 0.797 (or worse) occurs in 11% of simulations, i.e. an 11th percentile outcome. That’s a bit higher than what the first approach showed.
How can we feel confident about this approach? Well, in the first approach, we implicitly assumed that the performance ratio percentiles should be uniform across all players, hence the percentile ranking. We should see if the same bears out with this second approach.
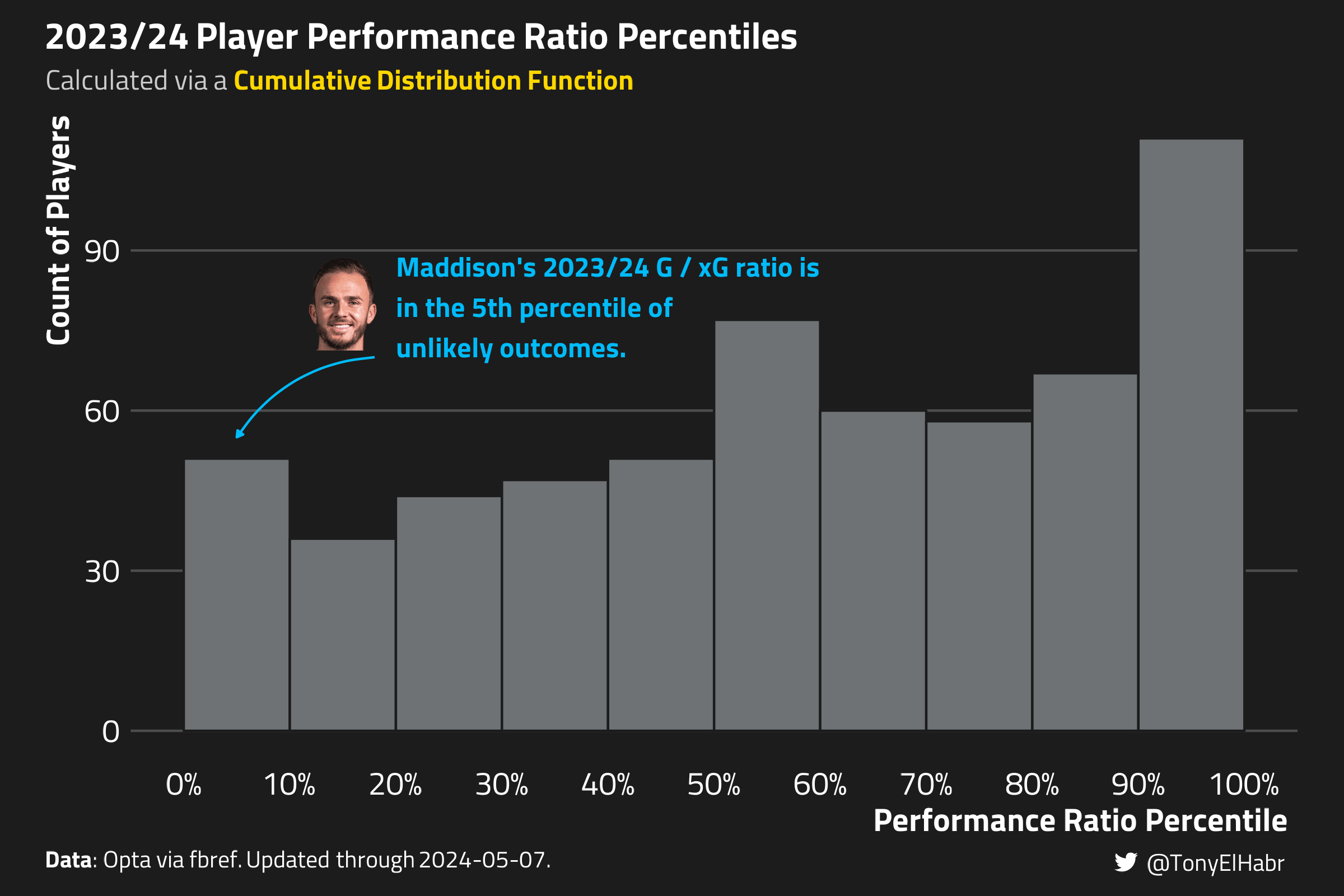
The plot below shows a histogram of the performance ratio percentile across all players, where each player’s estimated performance ratio percentile is grouped into a decile.
Approach 2 implementation for all players
all_resampled_pr <- np_shots |>resample_player_pr(players = all_players_to_evaluate$player ) |> dplyr::inner_join( wide_player_np_shots |>## to make sure we just one Rodri, Danilo, and Nicolás González dplyr::filter(player_id %in% all_players_to_evaluate$player_id) |> dplyr::select( player, prior_pr, target_pr, prior_shots, target_shots ),by = dplyr::join_by(player) ) |> dplyr::arrange(player, player)all_prp_approach2 <- all_resampled_pr |> dplyr::summarize(.by =c(player, prior_pr, target_pr, prior_shots, target_shots),prp =sum(pr <= target_pr) / dplyr::n() ) |> dplyr::arrange(prp)
Indeed, the histogram shows a fairly uniform distribution, with a bit of irregularity at the upper end.
Looking at who is in the lower end of the leftmost decile, we see some of the same names–Immobile and Savanier–among the ten underperformers. Withholding judgment on the superiority of any methodology, we can find some solace in seeing some of the same names among the most unlikely underperformers here as we did with approach 1.
One familiar face in the printout above is Manchester City’s striker Erling Haaland, whose underperformance this season has been called out among fans and the media. His sub-par performance this year ranked as a 9th percentile outcome by approach 1, which is very low, but not quite as low as what this approach finds (1st percentile).
Discussion
Assumption of shot profile consistency: We assume that a player’s past shot behavior accurately predicts their future performance. This generally holds unless a player changes their role or team, or is recovering from an injury. But there are other exceptions as well. For example, Haaland has taken a lot more headed shots this season, despite playing effectively the same role on mostly the same team from last season The change in Haaland’s shot profile this year conflicts with the assumption of a consistent shot profile, perhaps explaining why this resampling approach finds Haaland’s shooting performance to be more unlikely the percentile ranking approach.
Non-parametric nature: This method does not assume any specific distribution for a player’s performance ratios; instead, it relies on the stability of a player’s performance over time. The resampling process itself shapes the outcome distribution, which can vary significantly between players with different shooting behaviors, such as a forward versus a defender.
Computational demands: The resampling approach requires relatively more computational resources than the prior approach, especially without parallel processing. Even a relatively small number of resamples, such as \(R=1000\), can take a few seconds per player to compute.
Approach 3: Evaluating a Player-Specific Cumulative Distribution Function (CDF)
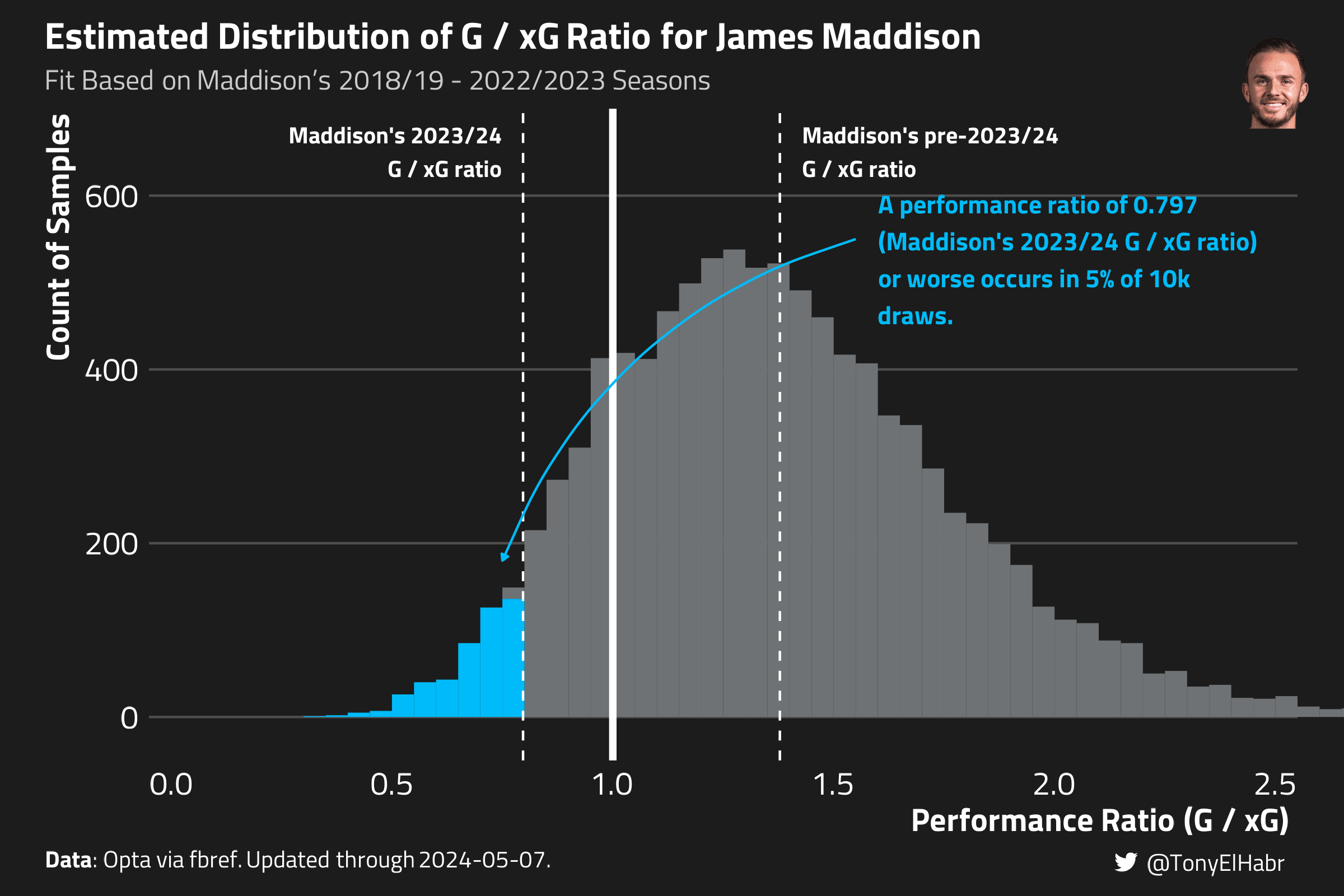
If we assume that the set of goals-to-xG ratios come from a Gamma data-generating process, then we can leverage the properties of a player-level Gamma distribution to assess the likelihood of a player’s observed goals-to-xG ratio.
To calculate the performance ratio percentile \(PRP_p\):
Estimate a Gamma distribution \(\Gamma_{p,\text{target}'}\) to model a player’s true outperformance ratio \(PR_{p,\text{target}'}\) across all prior shots, excluding those in the target season–\(\hat{PR}_{p,\text{target}'}\).
Calculate the probability that \(\hat{PR}_{p,\text{target}'}\) is less than or equal to the player’s observed \(PR_{p,\text{target}}\) in the target season using the Gamma distribution’s cumulative distribution function (CDF).
While that may sound daunting, I promise that it’s not.
Approach 3 implementation
SHOT_TO_SHAPE_MAPPING <-list('from'=c(50, 750),'to'=c(1, 25))## Fix the gamma distribution's "median" to be shaped around the player's past## historical G/xG ratio (with minimum shape value of 1, so as to prevent a ## monotonically decreasing distribution function).## Fit larger shape and rate parameters when the player has a lot of prior shots, ## so as to create a tighter Gamma distibution.estimate_one_gamma_distributed_pr <-function( shots, target_season_end_year) { player_np_shots <- shots |> dplyr::mutate(is_target = season_end_year == target_season_end_year) prior_player_np_shots <- player_np_shots |> dplyr::filter(!is_target) target_player_np_shots <- player_np_shots |> dplyr::filter(is_target) agg_player_np_shots <- player_np_shots |> dplyr::summarize(.by =c(is_target),shots = dplyr::n(), dplyr::across(c(g, xg), \(.x) sum(.x)) ) |> dplyr::mutate(pr = g / xg) agg_prior_player_np_shots <- agg_player_np_shots |> dplyr::filter(!is_target) agg_target_player_np_shots <- agg_player_np_shots |> dplyr::filter(is_target) shape <- dplyr::case_when( agg_prior_player_np_shots$shots < SHOT_TO_SHAPE_MAPPING$from[1] ~ SHOT_TO_SHAPE_MAPPING$to[2], agg_prior_player_np_shots$shots > SHOT_TO_SHAPE_MAPPING$from[2] ~ SHOT_TO_SHAPE_MAPPING$to[2],TRUE~ scales::rescale( agg_prior_player_np_shots$shots, from = SHOT_TO_SHAPE_MAPPING$from, to = SHOT_TO_SHAPE_MAPPING$to ) )list('shape'= shape,'rate'= shape / agg_prior_player_np_shots$pr )}estimate_gamma_distributed_pr <-function( shots, players, target_season_end_year) { purrr::map_dfr( players, \(.player) { params <- shots |> dplyr::filter(player == .player) |>estimate_one_gamma_distributed_pr(target_season_end_year = target_season_end_year )list('player'= .player,'params'=list(params) ) } )}maddison_gamma_pr <- np_shots |>estimate_gamma_distributed_pr(players ='James Maddison',target_season_end_year = TARGET_SEASON_END_YEAR ) |> dplyr::inner_join( wide_player_np_shots |> dplyr::select( player, prior_pr, target_pr ),by = dplyr::join_by(player) ) |> dplyr::arrange(player)maddison_prp_approach3 <- maddison_gamma_pr |> dplyr::mutate(prp = purrr::map2_dbl( target_pr, params, \(.target_pr, .params) {pgamma( .target_pr, shape = .params$shape, rate = .params$rate,lower.tail =TRUE ) } ) ) |> tidyr::unnest_wider(params)
Approach 3 output for Maddison
maddison_prp_approach3 |> dplyr::select(player, prior_pr, target_pr, prp)#> # A tibble: 1 × 4#> player prior_pr target_pr prp#> <chr> <dbl> <dbl> <dbl>#> 1 James Maddison 1.38 0.797 0.0469
We see that Maddison’s 2023/24 \(PR_{p,\text{target}}\) ratio of 0.797 (or worse) is about a 5th percentile outcome given his prior shot history.
To gain some intuition around this approach, we can plot out the Gamma distributed estimate of Maddison’s \(PR_p\). The result is a histogram that looks not all that dissimilar to the one from before with resampled shots, just much smoother (since this is a “parametric” approach).
As with approach 2, we should check to see what the distribution of performance ratio percentiles looks like–we should expect to see a somewhat uniform distribution.
This histogram has a bit more distortion than our resampling approach, so perhaps it’s a little less calibrated.
Looking at the top 10 strongest underperformers, 2 of the names here–VollandSanabria–are shared with approach 2’s top 10, and 7 are shared with approach 1’s top 10.
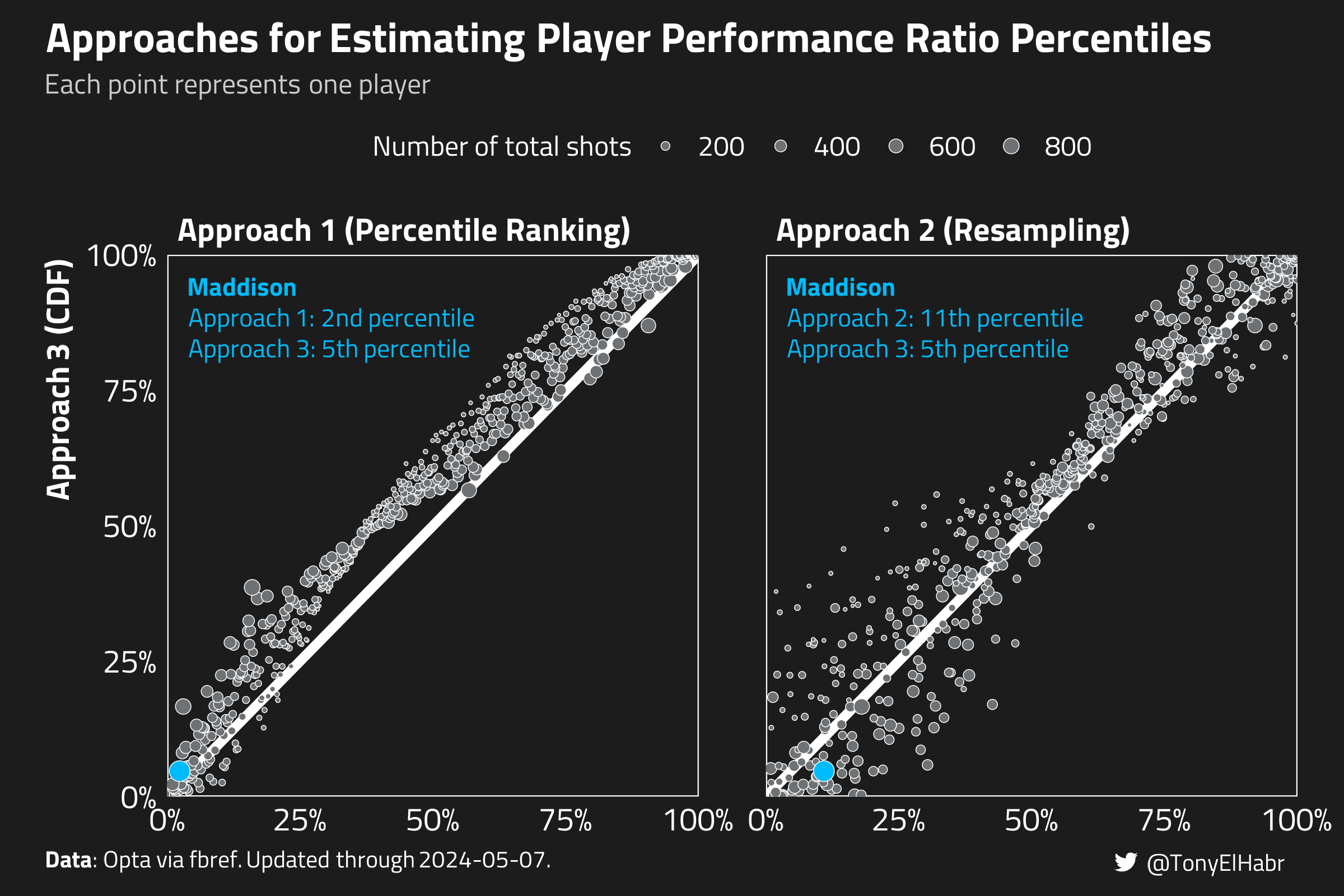
We can visually check the consistency of the results from this method with the prior two with scatter plots of the estimated performance ratio percentile from each.
If two of the approaches were perfectly in agreement, then each point–representing one of the 602 evaluated players–would fall along the 45-degree slope 1 line.
With that in mind, we can see that approach 3 more precisely agrees with approach 1, although approach 3 tends to assign slightly higher percentiles to players on the whole. The results from approaches 2 and 3 also have a fair degree of agreement, and the results are more uniformly calibrated.
Discussion
Parametric nature: The reliance on a Gamma distribution for modeling a player’s performance is both a strength and a limitation. The Gamma distribution is apt for positive, skewed continuous variables, making it suitable for modeling goals-to-xG ratios. And we can leverage the properties of the distribution to calculate a likelihood percentile directly. However, the dependency on a distribution is sort of an “all-or-nothing” endeavor–if we don’t estimate an appropriate distribution, then we can under- or over-estimate the likelihood of individual player outcomes.
Sensitivity to distribution parameters: The outcomes of this methodology are highly sensitive to the parameters defining each player’s Gamma distribution. Small adjustments in shape or rate parameters can significantly alter the distribution, causing substantial shifts in the percentile outcomes of player performances. This sensitivity underscores the need for careful parameter selection and calibration.
Conclusion
Here’s a summary of the biggest pros and cons of each approach, along with the result for Maddison.
Approach
Description
Pros
Cons
James Maddison 2023/24 Performance Ratio Percentile
1
Weighted percentile ranking
Easy to understand and implement
Sensitive to the weighting scheme and the set of evaluated players
2nd percentile
2
Resampling from prior shot history
Non-parametric (no need to make a choices about weighting scheme, distribituion fitting, etc.)
Assumes a player’s shot profile is static, can be computationally intensive
11th percentile
3
Evaluating a player-specific cumulative distribution function (CDF)
Likelihood of an outcome can be calculated directly from the properties of the distribution
Sensitive to choice of distribution parameters
5th percentile
I personally prefer either the second or third approach. In practice, perhaps the best thing to do is take an ensemble average of each approach, as they each have their pros and cons.
Potential Future Research
Can these approaches be applied to teams or managers to understand the unlikeliness of their season-long outcomes?
I think the answer is “yes”, for the resampling approach. The non-parametric nature of resampling makes it easy to translate to other “levels of aggregation”, i.e. a set of players under a manager or playing as a team.
Can we accurately attribute a percentage of the underperformance to skill and luck?
Eh, I don’t know about “accurately”, especially at the player level.The R-squared of year-over-year player-level G / xG ratios is nearly zero. If we equate “skill” to “percent of variance explained in year-over-year correlations of a measure (i.e. G / xG)”, then I suppose the answer is that basically 0% of seasonal over- or under-performance is due to innate factors; rather, we’d attribute all variation to “luck” (assuming that their “skill” and “luck” are the only factors that can explain residuals). That’s not all that compelling, although it may be the reality.
My prior work on “meta-metrics” for soccer perhaps has a more compelling answer. The “stability” measure defined in that post for \(G / xG\) comes out to about 70% (out of 100%). If we say that “stability” is just another word for “skill”, then we could attribute about 70% of a player’s seasonal over- or under-performance to innate factors, on average.
Appendix
Approach 0: \(t\)-test
If you have some background in statistics, applying a \(t\)-test (using shot-weighted averages and standard deviations) may be an approach that comes to mind.
Approach 0
prp_approach0 <- player_season_np_shots |> dplyr::semi_join( all_players_to_evaluate |> dplyr::select(player_id),by = dplyr::join_by(player_id) ) |> dplyr::filter(season_end_year < TARGET_SEASON_END_YEAR) |> dplyr::summarise(.by =c(player),mean =weighted.mean(pr, w = shots),## could also use a function like Hmisc::wtd.var for weighted variancesd =sqrt(sum(shots * (pr -weighted.mean(pr, w = shots))^2) /sum(shots)) ) |> dplyr::inner_join( wide_player_np_shots |> dplyr::select(player, prior_pr, target_pr),by = dplyr::join_by(player) ) |> dplyr::mutate(z_score = (target_pr - mean) / sd,## multiply by 2 for a two-sided t-testprp =pnorm(-abs(z_score)) ) |> dplyr::select(-c(mean, sd)) |> dplyr::arrange(player)
Approach 0 output
prp_approach0 |> dplyr::filter(player =='James Maddison') |> dplyr::select(player, prior_pr, target_pr, prp)#> # A tibble: 1 × 4#> player prior_pr target_pr prp#> <chr> <dbl> <dbl> <dbl>#> 1 James Maddison 1.38 0.797 0.0543
In reality, this isn’t giving us a percentage of unlikelihood of the outcome. Rather, the p-value measures the probability of underperformance as extreme as the underperformance observed in 2023/24 if the null hypothesis is true. The null hypothesis in this case would be that there is no significant difference between the player’s actual \(PR_p\) in the 2023/24 season and the distribution of performance ratios observed in previous seasons.
No matching items
Footnotes
I only consider non-penalty xG and goals for this post. The ability to score penalties at a high success rate is generally seen as a different skill set than the ability to score goals in open play.↩︎
The raw difference between goals and xG is a reasonable measure of shooting performance, but it can “hide” shot volume. Is it fair to compare a player who takes 100 shots in a year and scores 12 goals on 10 xG with a player who takes 10 shots and scores 3 goals on 1 xG? The raw difference is +2 in both cases, indicating no difference in the shooting performance for the two players. However, their \(PR_p\) would be 1.2 and 3 respectively, hinting at the former player’s small sample size.↩︎
The weighting emphasizes scenarios where a veteran player, typically overperforming or at worst neutral, suddenly underperforms, as opposed to a second-year player experiencing similar downturns.↩︎
Percentiles greater than 50% generally correspond with players who have overperformed, so really the bottom 50% are the players we’re looking at when we’re considering underperformance.↩︎
\(N_p\) should be set equal to the number of shots a player has taken in the target season. \(R\) should be set to some fairly large number, so as to achieve stability in the results.↩︎