Using empirical Bayes and the Gamma-Poisson conjugate pair
Author
Tony ElHabr
Published
August 28, 2023
Modified
April 26, 2024
Updates
Wording in this post was updated after the original posting. Originally an outperformance ratio greater than 1 was mistakenly called “underperforming”, and a ratio less than 1 was mistakenly called “overperforming”. The wording has been fixed.
Introduction
This blog post is my attempt to replicate the results in Laurie Shaw’s 2018 blog post “Exceeding Expected Goals”. Specifically, I want to shed light on how to implement Gamma-Poissonempirical Bayes (EB) estimation. If you don’t care at all about the theory behind EB and its application to this context, then go ahead and skip ahead to the “Implementation” section.
What Is Empirical Bayes (EB) estimation?
Empirical Bayes (EB) estimation. Wow, just typing that out makes me feel smart. But what is it, really? In short, I’d describe it as a mix of Bayesian and Frequentist inference. We lean into the observed frequencies of the data (Frequentist) while simultaneously refining our initial data assumptions through Bayesian updating. In practice, one might use EB as a (relatively) simple alternative to a full Bayesian analysis, which can feel daunting.
In regular Bayesian analysis, you start with your initial “guess” (prior distribution) about something, and as you gather data, you tweak that “guess” using Bayes’ theorem to get a final view (posterior distribution). We combine what we thought about the data beforehand with how likely the data matches (likelihood).
Empirical Bayes puts a twist on this. Instead of having a prior guess, you figure out that initial guess from the same data you’re analyzing. This can make things simpler, especially when you’re dealing with tons of guesses but not much initial info.
A canonical example of EB estimation (Beta-Binomial)
David Robinson wrote a wonderful blog post about empirical Bayes estimation for estimating batting averages in baseball, notably “shrinking” the battering averages of those with relatively few at bats closer to some “prior” estimate derived from a choice of hyperparameters. For context, batting average, \(BA\), is defined as a player’s count of hits, \(H\), divided by the count of their at bats, \(AB\).
\[
BA = \frac{H}{AB}
\tag{1}\]
Note
I’d David’s post must read material before going through this blog post.
In his post, David uses a Beta prior and a binomial posterior together, i.e. a Beta-binomial Bayesian model)12, since this tandem is suitable for proportions and probabilities. The gist of his approach: we add some fixed number of hits, \(\alpha_0\), and a fixed number of at bats, \(\beta_0\), to the numerator and denominator of the battering average equation as so.
Specifically, the “prior” estimate of batting average is found by isolating the \(\alpha_0\) and \(\beta_0\) elements:
\[
\frac{\alpha_0}{\alpha_0 + \beta_0}
\tag{3}\]
If, for example, alpha0 = 70 and beta0 = 163, then the prior estimate of batting average is effectively 70 / (70 + 163) = 0.3. Note that alpha0 and beta0 are learned from the data using maximum likelihood estimation (MLE), although other approaches, such as “method of moments” could be used. (Heck, you could even defensibly choose these “hyperparameters” yourself, without any fancy statistics, if you feel that you have enough knowledge of the data.)
Gamma-Poisson EB estimation
Now, for my replication of Shaw’s analysis, we’re going to be focusing on the ratio of a player’s goals, \(G\), divided by their expected goals), \(xG\), summed up over a fixed period. Shaw refers to this as “outperformance” \(O\) for a player \(p\):
\[
O_p = \frac{G_p}{xG_p}
\tag{4}\]
While one might be tempted to use Beta-Binomial EB since this setup seems similar to batting average in Equation 1, Shaw used a Gamma-Poisson EB adjustment, and justifiably so. Gamma-Poisson makes more sense when the underlying data consists of counts and what you’re trying to estimate is a rate or ratio, not a proportion bounded between 0 and 1. Note that a \(O_p\) ratio of 1 indicates that a player is scoring as many goals as expected; a ratio greater than 1 indicates overperformance; and a ratio less than 1 indicates underperformance. On, the other hand, batting average is bounded between 0 and 1.
Now, despite the naming of conjugate prior pairs–e.g. “Beta-Binomial” and “Gamma-Poisson”, where the prior distribution is represented by the first distribution and the likelihood distribution is indicated by the second–let’s not forget that there is a third distribution to be noted: the posterior. In the case of the Gamma-Poisson model, the unnormalized posterior distribution of the “kernel” (i.e. the prior and likelihood pair) is a Gamma distribution. (This is always the case with Gamma-Prior kernels.)
In practice, this means that we’ll be using the Gamma distribution for both estimating hyperparameters and posterior sampling. Perhaps surprising to the reader, you won’t need any Poisson functions in the code implementation. Rather, the Poisson distribution is pertinent to implementation only to the extent that the Gamma distribution happens to be the most reasonable distribution to pair with it.
I’ve woefully explained away a lot of details here, but hopefully this all makes sense to those with a basic understanding of the Gamma and Poisson distributions themselves.
Implementation
Ok, so with all of that context provided, now let’s do the replication of Shaw’s findings.
Note that Shaw used data from a provider, Stratagem, that no long provides data, as far as I can tell. For at least this reason, I won’t be able to exactly match his reason.5
Code
## data wranglinglibrary(worldfootballR)library(dplyr)library(tibble)## distribution fitting and wranglinglibrary(MASS, include.only ='fitdistr') ## to avoid `select` name conflict with dplyrlibrary(withr)library(purrr)library(tidyr)raw_shots <- worldfootballR::load_understat_league_shots(league ='EPL')shots <- raw_shots |> tibble::as_tibble() |> dplyr::filter( season %in%c(2016L, 2017L), ## 2016/17 and 2017/18 seasons situation !='DirectFreeKick'## "excluding free-kicks" in the blog post ) |> dplyr::arrange(id) |> dplyr::transmute( id, player,xg = x_g,g =as.integer(result =='Goal') )shots#> # A tibble: 19,047 × 4#> id player xg g#> <dbl> <chr> <dbl> <int>#> 1 112088 Aaron Ramsey 0.0695 0#> 2 112089 Nathaniel Clyne 0.0293 0#> 3 112090 Aaron Ramsey 0.00734 0#> 4 112091 Roberto Firmino 0.0856 0#> 5 112092 Roberto Firmino 0.0441 0#> 6 112093 Sadio Mané 0.0607 0#> 7 112094 Ragnar Klavan 0.0742 0#> 8 112095 Theo Walcott 0.761 0#> 9 112096 Theo Walcott 0.0721 1#> 10 112097 Roberto Firmino 0.0241 0#> # ℹ 19,037 more rows
Above was pulling in every record of shots, with 1 row per shot. Now we aggregate to the player level, such that we have one row per player.
Next, we estimate hyperparameters for our prior gamma distribution using MLE. (With R’s dgamma, the hyperparameters are shape and rate6). I subset the data down to players having taken at least 50 shots for estimating these hyperparameters, as this is what Shaw does. In general, you’d want to filter your data here to records that provide good “signal”, and, therefore, will provide reliable estimates of your hyperparameters.7
EB step 2: Use prior distribution to sample the posterior
Now we use our prior distribution’s hyperparameters to update all players’ \(O\) ratio based on their individual volume of evidence, i.e. their goals and xG.
Finally, let’s plot our results, plotting our adjusted mean estimates of \(O_p\), ±1 standard deviation about the adjusted mean.8 As noted earlier, we won’t achieve exactly the same results as Shaw due to using a different set of xG values, but evidently we’ve achieved results reasonably close to his.
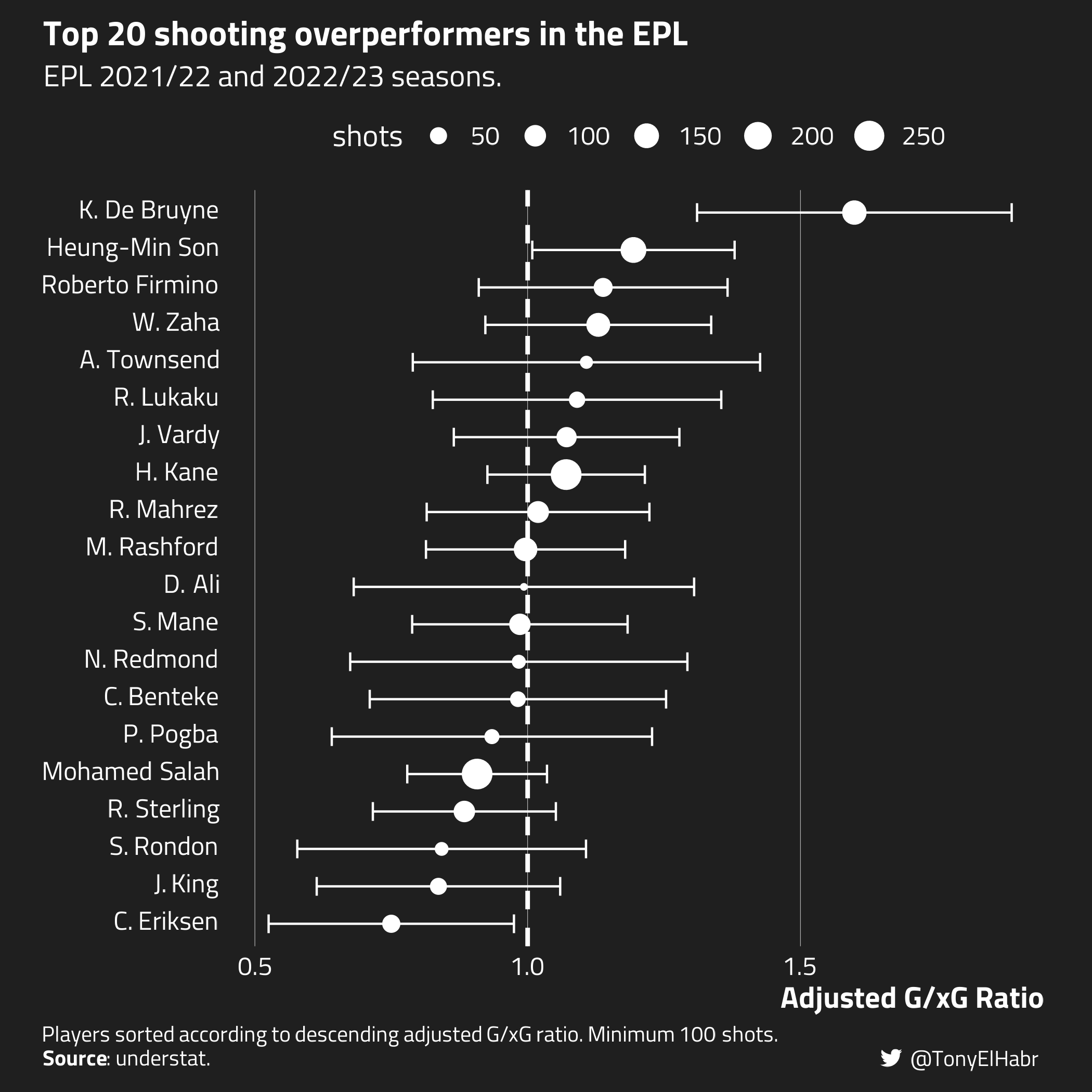
For the sake of having a pretty plot that’s not just an attempt to replicate the original, let’s run it all back, this time with EPL 2021/22 and 2022/23 data.
For those who follow the EPL, The usual suspects, like Heung-Min Son, show up among the best of the best HERE. The adjusted mean minus one standard deviation value exceeds zero for Son, so one might say that he was a significantly skilled shooter over the past two season.9
Conclusion
Having not seen a very clear example of Gamma-Prior EB implementation on the internet–although there are several good explanations with toy examples such as this e-book chapter from Hyvönen and Topias Tolonen–I hope I’ve perhaps un-muddied the waters for at least one interested reader.
As for the actual application of \(G / xG\) for evaluating shooting performance, I have mixed feelings about it. Further analysis shows that it has zero year-over-year stability, i.e. one shouldn’t use a player’s raw or adjusted G/xG ratio in one season to try to predict whether their outperformance ratio will sustain in the next season. On the other hand, by simply making player estimates more comparable, the EB adjustment of \(O_p\) certainly is an improvement over raw \(G / xG\) itself.
Comparing hypothetical player A with 6 goals on 2 xG (\(O_p = 3\)) vs. player B with 120 goals on 100 xG directly (\(O_p = 1.2\)) is unfair; the former could be performing at an unsustainable rate, while the latter has demonstrated sustained overperformance over a lot more time. Indeed, applying the EB adjustment to these hypothetical numbers, player A’s \(O_p\) would be shrunken back towards 1, and player B’s adjustment would be effectively nothing, indicating that player B’s shooting performance is stronger, on average.
No matching items
Footnotes
This conjugate distribution table might be handy for those curious to know which distributions are typically paired together for empirical Bayes estimation.↩︎
If you’ve seen my work, you might have noticed that I’ve used Beta-Binomial EB a few times for public projects in the past:
Note that understat maintains its own xG model, so the xG on understat won’t exactly match what you might get from Opta or StatsBomb.↩︎
FBRef only provides expected goals dating back to the 2017/18 season, so unfortunately it’s not viable for this analysis.↩︎
The other major reason why I may not be able to match his results is if I’ve implemented the Gamma-Poisson adjustment in a different (hopefully, not incorrect 😅) manner.↩︎
In the wild, you’ll see alpha and beta used to describe the hyperparameters. shape and rate are different ways of framing these parameters.↩︎
Note that this process of selecting priors is the “twist” I mentioned in the introduction that really separates empirical Bayes estimation from a traditional, full Bayesian approach. In the latter, one chooses priors for an analysis without using the data to be included in the analysis.↩︎
This post isn’t meant to be about uncertainty and credible intervals for EB adjusted means, so I won’t go into it here. Loosely, one can read the interval as quantifying the bound about which we can be confident that the true estimate lands. Uncertainty intervals that overlap with 1 broadly suggest that, even though the mean estimate may look to be much greater or less than 1, we cannot say the difference is significant from the “average” (of 1).↩︎
A more strict and, arguably, correct measure is a 90 or 95% credible interval to ascertain “significance”. Nonetheless, to maintain consistency with Shaw, I’m showing standard deviation.↩︎